


'분류 전체보기'에 해당되는 글 199건
2010. 2. 9. 11:26
오늘 갑자기 MySQL에 데이터를 Load하는데 "ERROR 13 (HY000): Can't get stat of '/home/....' (Errcode: 13)" 이와같은 에러가 나는것이다.
이런 이건 또 머야..??
바로 구글링에 들어가서 찾은 결과!
ㅋㅋㅋㅋ
아주 간단하다 파일을 읽을 수 있는 권한이 없는것이다. 파일의 권한뿐만 아니라 그 파일을 찾으로 가는 각각의 Path에 속해있는 폴더의 권한도 마찮가지다!
ㅋㅋㅋㅋㅋ
이저먹지 말자!!!
이런 이건 또 머야..??
바로 구글링에 들어가서 찾은 결과!
ㅋㅋㅋㅋ
아주 간단하다 파일을 읽을 수 있는 권한이 없는것이다. 파일의 권한뿐만 아니라 그 파일을 찾으로 가는 각각의 Path에 속해있는 폴더의 권한도 마찮가지다!
ㅋㅋㅋㅋㅋ
이저먹지 말자!!!
'ººº::Development™:: > ::Database™::' 카테고리의 다른 글
| [SQL] Sql-like 구문 (0) | 2009.11.11 |
|---|---|
| [ODBC] Linux에서 MS-SQL 접속하기 (0) | 2008.10.30 |
| [ER-Win] ERWin에서 MS-SQL 연결하기 (10) | 2008.10.08 |
| MySql Error - Client does not support authentication protocol requested by Server (0) | 2007.06.26 |
| MySQL Connection Error (0) | 2007.05.28 |
2010. 2. 4. 10:41
이전에 Blast 설치 포스트에 보면 마지막에 Blast search를 간단하게 설명했었다. 오늘은 그 Blast search중 프로그램을 선택하는 부분이 있는데 그 프로그램이 어떤것들이 있는지 알아보겠다.
Blast의 5가지 프로그램
- blastp : 단백질 – 단백질 비교 / 관련성이 먼 것을 찾기 위해 치환행렬 사용
- blastn : 염기 – 염기 비교 / 관련성이 멀지 않으며 아주 점수가 높은 매치에 사용
- blastx : 염기(번역) – 단백질 비교 / 새로운 DNA 서열 및 EST 분석에 응용
- tblastn : 단백질 – 염기(번역) 비교 / DB중 코딩 부위를 찾는데 유용함
- tblastx : 염기(번역) – 염기(번역) 비교 / EST분석에 유용하나 많은 계산을 요함
'ººº::Learning™:: > ::BioInformatics™::' 카테고리의 다른 글
2010. 1. 15. 15:18
BLAST는 서열들 중 유사성을 갖는 부위를 찾는 프로그램으로 서열 데이터베이스에서 nucleotied 또는 proten sequence를 비교하고 매치되는 것들을 찾는다.
대학원 시절 이후로 다시 BLAST를 만지게 될지는 몰랐지만 앞으로 계속 자주 만져야 할거 같아서 처음부터 정리를 해보자 그 첫번째로 설치부터!!
BLAST는 웹사에서 사용할 수 있는 Web BLST와 사용자 컴퓨터 혹은 서버에서 사용 가능한 Local BLAST로 나뉠 수 있다. 그중에서 이번에는 Local BLST설치 및 사용법에 대해 정리해 보자( 사실 Web BLAST는 어찌 설치했는지 기억이 안나서~~ㅋㅋㅋ)
1. BLAST Download & Install
BLAST는 NCBI FTP 사이트에서 다운로드 받을 수 있다. 자신의 컴퓨터 OS 버전에 따라 원하는 BLAST를 다운로드 받는다.(이곳에서는 Linux를 기반으로 설명한다.)
원하는 버전의 BLAST를 다운로드 받았으면 원하는 폴더에 압축을 푼다.
2. Local BLAST를 이용한 Sequence Search
1. 먼저 검색할 서열 데이터베이스가 필요하다. 이는 원하는 서열 데이터베이스를 NCBI혹은 해당 사이트로 부터 다운받자
2. 다운받은 Raw데이터 혹은 Fasta 형식의 데이터를 이용해 BLAST에서 사용가능한 DB Format으로 변경을 하자. 이는 BLAST 검색 속도를 향상기키기 위해 필요한 단계이다.
# /usr/local/BLAST/formatdb -i [Data_path] a T -p [DNA/RNA]
위 명령은 사용자 환경에 따라 달라질 수 있으니 잘 확인하고 만드시길!특히 -p 옵션은 만들어지는 db가 nucleotide냐 protein이냐를 정하는 옵션이다. 이 옵션에 따라 blast program을 실행시킬 수 있다. default는 protein이니 blastn을 사용하기 위해서는 꼭 -p F 로 db를 만들어 주어야 한다.
3. BLAST Search
1. 첫번째로 검색하고자 하는 서열 정보를 Fasta format으로 만들어 준다.
>gi|84040121|gb|ABC49914.1
ACGTTTTTTTTTAAAAGAGAGAGAGAGCCCCCCCCC
2. BLAST를 이용해 검색한다.ACGTTTTTTTTTAAAAGAGAGAGAGAGCCCCCCCCC
# /usr/local/BLAST/blastall -p blastn -d /db_path -i sequence.fasta -o sequence.out
4. 검색된 결과를 확인한다.
'ººº::Learning™:: > ::BioInformatics™::' 카테고리의 다른 글
2010. 1. 11. 13:47
내가 지금 일하고 있는곳 서울대학교 유전체 의학 연구소에서 '아시안 게놈 로드' 프로젝트를 진행한다.
조선일보·서울대 유전체의학硏 '아시안 게놈 로드' 프로젝트
아시아 9개국 1000여명 DNA 유전정보 전체 해독
한국인의 눈에는 몽고주름이, 엉덩이에는 몽고반점이 있다. 몽골 사람이나 북미 인디언도 마찬가지다. 한국인과 북방계 유목민족의 연관성을 보여주는 증거다. 반면 고인돌과 솟대는 남방계 아시아인의 흔적이다. 유목민족은 석관묘를 쓴다. 한국인의 뿌리는 북방계인가, 남방계인가.

지난해 7월 서울대 의대 서정선 교수는 30대 한국인 남성의 게놈 전체를 해독한 결과를 '네이처'지에 발표했다. 서 교수는 "한국인은 앞서 게놈이 해독된 남방계 중국인과 뚜렷하게 구분되는 북방계 아시아인임을 확인했다"며 "아프리카인과 유럽인, 남방계 아시아인, 북방계 아시아인이라는 인류를 구성하는 4개 인종의 게놈정보를 완성한 것"이라고 밝혔다.
지난달 11일 한국생명공학연구원을 비롯한 국제컨소시엄이 '사이언스'지에 발표한 연구결과는 그와 정반대였다. 컨소시엄은 "아시아 73개 민족의 개인별 유전자 변이(SNP)를 분석한 결과, 아프리카에서 비롯된 인류의 조상이 인도 북부를 거쳐 동남아시아에 정착했고, 그 중 북쪽으로 이동한 한 갈래가 만주를 거쳐 한반도로 들어왔다"고 밝혔다. 한국인의 기원이 남방계란 말이다.
하지만 두 연구 모두 한계를 갖고 있다. 서 교수팀의 연구는 한국인의 게놈 전체를 해독했다는 점에서 의미가 있지만, 1명만 분석한 것이어서 대표성이 떨어진다. 사이언스지에 실린 연구는 분석대상이 방대하다는 점에서 서 교수팀을 앞서지만, 몽골이나 만주 등 북방계 아시아인은 분석하지 않아 '반쪽짜리 연구'라는 평가를 받고 있다.
조선일보와 서울대 유전체의학연구소가 함께 추진할 '아시안 게놈 로드'는 두 연구의 한계를 모두 극복할 것으로 기대된다. 북방계와 남방계 아시아 국가가 다 들어갔고, 해독 대상도 1000명이나 된다. 사이언스지 논문이 게놈의 극히 일부만 분석했지만, 아시안 게놈 로드는 게놈 전체를 해독할 계획이다. 규모와 정확도에서 명실상부한 최초의 '아시아인 유전자 지도'를 만들 수 있다.
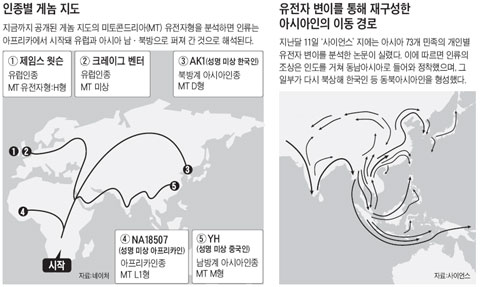
아시안 게놈 로드의 총책임자인 서정선 교수는 "현재로선 한국인의 DNA는 북방계와 남방계의 혼합형으로 추정된다"고 밝혔다. 이는 게놈 일부를 분석한 다른 연구에서 확인된다. 김욱 단국대 생체표지연구센터장은 아시아 각 민족의 미토콘드리아 유전자를 분석했다. 미토콘드리아는 세포핵 밖에 있는 기관으로 난자를 통해서만 후손에게 전달된다. 모계 혈통을 알 수 있다. 세포핵 유전자엔 모계와 부계가 섞여 있다.
미토콘드리아 DNA는 한국인의 60~70%가 북방계 유전자 특성을 보였다. 하지만 세포핵의 개인별 유전자 변이를 분석하면 반대로 60~70%가 남방계였다. 김 센터장은 "한국인은 북방계와 남방계가 혼합돼 형성된 것"이라며 "지난달 사이언스 논문은 약 3만~4만년 전에 남방계 인류가 한반도로 들어왔다는 것이지, 남방계가 한국인의 뿌리라는 의미는 아니다"라고 말했다.
남방계가 오기 전인 약 2만년 전에 이미 북방계가 한반도로 들어왔기 때문이다. 2008년 연세대 신경진 교수팀은 박물관에 있는 구석기·신석기·청동기·백제·신라·고려 시대의 유골 35점에서 미토콘드리아 DNA를 추출해 분석했다. 그 결과 선사시대 한국인의 DNA는 북방계의 특성을 보였으며, 남방계 DNA는 비교적 최근에 유입된 것으로 나타났다. 서정선 교수는 "아시안 게놈 로드는 게놈 전체를 해독해 북방계와 남방계의 혼합 과정을 더욱 세밀하게 보여 줄 것"이라고 말했다.

- ▲ 서울대학교·서정선 교수
◆아시아인용 맞춤 의약 토대 마련
아시안 게놈 로드는 한국인의 기원을 밝혀줄 뿐 아니라 아시아인용 맞춤 의약의
토대도 마련할 것으로 기대된다. 같은 약이라도 아시아인과 서양인에서 효능이 다르게 나타난다는 사실이 잇따라 확인되면서 다국적 제약사들의 아시아
임상시험이 크게 늘고 있다. 한 예로 아스트라제네카가 1996년 개발한 폐암치료제 '이레사'는 서양인 대상 임상시험에서는 별 효과가 없었지만,
아시아인에서는 말기 폐암 환자들에게 효과가 있는 것으로 나왔다. 또 노바티스의 고혈압 치료제 '디오반'은 아시아인 대상 임상시험에서 뇌졸중
예방효과가 입증됐다. 아시안 게놈 로드를 통해 아시아인 고유의 유전적 특성이 밝혀지면, 아시아인에게 맞는 약품이나 치료법이 개발될 수 있다.
휴가 댕겨왔더니 이런 기사가!!.. 아직 많은것이 부족한데 좀더 공부하고 남들보다 한발 앞서서!!
'ººº::Learning™:: > ::BioInformatics™::' 카테고리의 다른 글
2010. 1. 5. 20:49














'ººº::Photo™:: > ::상현지환™::' 카테고리의 다른 글
| [돌잔치] 12달 액자 (0) | 2009.11.06 |
|---|---|
| [돌잔치] 얼짱 이벤트 응모용!! (0) | 2009.10.25 |
| [포포상현] =ㅅ= 100일사진프로젝트!! (0) | 2009.03.31 |
| [포포상현] =ㅅ= 100일사진프로젝트!! (2) | 2009.03.31 |
2009. 12. 30. 18:04
아이폰이 필요하나 돈이 없으신분 한번 도전해보세요!!
네이버에서 통크게 아이폰 100대를 이벤트 경품으로 내놨네요!!

네이버에서 통크게 아이폰 100대를 이벤트 경품으로 내놨네요!!
'ººº::Information™:: > ::zEtc™::' 카테고리의 다른 글
| [ 크롬 앱 ] 네이트온 원격연결 이제 안녕!!! (0) | 2012.10.09 |
|---|---|
| [툴] Fedora10에서 mplayer설치하기 (2) | 2009.05.07 |
| [Tip] 블로그에 LaTex 수식 입력하기 (8) | 2009.04.24 |
| [툴] 웹에서 무료로 동영상 편집을...?? (0) | 2009.04.01 |
| [Tip] 이름을 분석하자 (0) | 2009.03.30 |
2009. 11. 11. 17:01
자바스크립트를 사용하다보면 문자열에서 특정 위치의 문자를 가져오는 substr혹은 substring을 사용할때가 있다.
그런데 사용하다보면 substr과 substring의 결과가 틀리게 나오는것을 알 수 있을 것이다. 아마도 substr혹은 substring을 사용하는 사람별로 각자 원하는 방식대로 사용하고 있을 것이다.(머 나부터두 그러니!ㅋㅋ)
그럼 이 둘의 차이점을 간단히 알아보자
머 말보다는 항상 코드와 결과가 이해하는데 빠르다.
자 그럼 위 코드의 결과를 살펴보면 substring은 2번째 문자열부터 4번째 문자열까지 즉 "cd"가 출력될 것이다. 하지만 substr은 2번째 문자열 이후부터 4자리를 잘라내라는 뜻으로 "cdef"가 출력될것이다.
자 이제 간단한 차이점을 알아봤으니 각자 원하는 취향대로 사용하자~~^^;;
그런데 사용하다보면 substr과 substring의 결과가 틀리게 나오는것을 알 수 있을 것이다. 아마도 substr혹은 substring을 사용하는 사람별로 각자 원하는 방식대로 사용하고 있을 것이다.(머 나부터두 그러니!ㅋㅋ)
그럼 이 둘의 차이점을 간단히 알아보자
1. substring : 어디부터 어디까지 잘라내겠다.(java의 substring과 같다)
2. substr : 어디부터 몇번째까지 잘라내겠다.
2. substr : 어디부터 몇번째까지 잘라내겠다.
머 말보다는 항상 코드와 결과가 이해하는데 빠르다.
var str = "abcdefg";
alert("substring : " + str.substring(2, 4)); // "cd"가 잘려 나온다.
alert("substr : " + str.substr(2, 4)); // "cdef"가 잘려 나온다.
alert("substring : " + str.substring(2, 4)); // "cd"가 잘려 나온다.
alert("substr : " + str.substr(2, 4)); // "cdef"가 잘려 나온다.
자 그럼 위 코드의 결과를 살펴보면 substring은 2번째 문자열부터 4번째 문자열까지 즉 "cd"가 출력될 것이다. 하지만 substr은 2번째 문자열 이후부터 4자리를 잘라내라는 뜻으로 "cdef"가 출력될것이다.
자 이제 간단한 차이점을 알아봤으니 각자 원하는 취향대로 사용하자~~^^;;
:: 이 글을 읽는 모든 분들에게 즐겁고 행복만이 가득하기를 ::
'ººº::Development™:: > ::WEB™::' 카테고리의 다른 글
| [Javascript] 실수 소수점 처리 - 반올림, 버림 (0) | 2009.10.01 |
|---|---|
| [PHP] 내림 / 올림 / 반올림 함수 (0) | 2009.07.09 |
| [CSS] 메뉴를 손쉽게 꾸며보자 (0) | 2008.09.23 |
| [Javascript] Dragtable - Table정렬 스크립트.. (0) | 2008.07.16 |
| [JavaScript] Giva Labs이 만든 콤보박스 (0) | 2008.07.09 |
2009. 11. 11. 16:48
SQL을 사용하다보면 특정 문자열이 틀어간 모든 데이터를 검색하고 싶은 경우에 사용하는 like구문이 있을것이다. 그런데 오늘 문득 이 구문을 사용해 쿼리문을 작성하다가 특정 위치에 특정 문자가 존재하는 경우만을 검색하고자 하는 문제가 발생했다.
보통 %를 사용해서 특정 문자나 문자열이 들어가는 모든 내용을 가져오는것은 대부분 알고 있을 것이다.
그런데 이런 내용은!!ㅠㅠ; 역시 많은 프로젝트를 통해 많은 경험을 쌓아야만 하는것인가 하는 생각이 들면서 바로 구글링을 통해 알아본 결과 '_'라는 라는 내용이 있다.
즉 특정 위치의 내용은 무시하면서 검색을 할 수 있는 방법이다. 머 100마니 글보다 한번 보고 한번 해보는것이 좋을것이다.
1, 2번 쿼리 같은 경우는 모두 아고 있듯이 중간에 2가 들어간 모든 결과 혹은 4로 시작하는 모든 내용을 가져오라는 뜻이다. 하지만 3번 같은 경우는 첫번째 와 3번째 자리의 번호가 4와 6으로 시작하는 모든 결과를 가져오는 것이다.
위의 3번 쿼리를 했을 경우의 결과는 아래와 같다.
위 쿼리를 바탕으로 특정 column이 코드 형태로 이루어졌을 경우 해당 코드의 값에 해당하는 내용을 가져올 수 있을 것이다.
보통 %를 사용해서 특정 문자나 문자열이 들어가는 모든 내용을 가져오는것은 대부분 알고 있을 것이다.
그런데 이런 내용은!!ㅠㅠ; 역시 많은 프로젝트를 통해 많은 경험을 쌓아야만 하는것인가 하는 생각이 들면서 바로 구글링을 통해 알아본 결과 '_'라는 라는 내용이 있다.
즉 특정 위치의 내용은 무시하면서 검색을 할 수 있는 방법이다. 머 100마니 글보다 한번 보고 한번 해보는것이 좋을것이다.
| FirstName | LastName | DOB | Phone | |
| John | Smith | John.Smith@yahoo.com | 2/4/1968 | 626 222-2222 |
| Steven | Goldfish | goldfish@fishhere.net | 4/4/1974 | 323 455-4545 |
| Paula | Brown | pb@herowndomain.org | 5/24/1978 | 416 323-3232 |
| James | Smith | jim@supergig.co.uk | 20/10/1980 | 416 323-8888 |
1. SELECT * FROM [table] WHERE Phone like '%2';
2. SELECT * FROM [table] WHERE Phone like '4%';
3. SELECT * FROM [table] WHERE Phone like '4_6%';
2. SELECT * FROM [table] WHERE Phone like '4%';
3. SELECT * FROM [table] WHERE Phone like '4_6%';
1, 2번 쿼리 같은 경우는 모두 아고 있듯이 중간에 2가 들어간 모든 결과 혹은 4로 시작하는 모든 내용을 가져오라는 뜻이다. 하지만 3번 같은 경우는 첫번째 와 3번째 자리의 번호가 4와 6으로 시작하는 모든 결과를 가져오는 것이다.
위의 3번 쿼리를 했을 경우의 결과는 아래와 같다.
| Paula | Brown | pb@herowndomain.org | 5/24/1978 | 416 323-3232 |
| James | Smith | jim@supergig.co.uk | 20/10/1980 | 416 323-8888 |
위 쿼리를 바탕으로 특정 column이 코드 형태로 이루어졌을 경우 해당 코드의 값에 해당하는 내용을 가져올 수 있을 것이다.
:: 그럼 이글을 읽는 모든 분들에게 행복이 가득하기를 ::
'ººº::Development™:: > ::Database™::' 카테고리의 다른 글
| [MySql] LOAD DATA INFILE get error 13 (HY000) (0) | 2010.02.09 |
|---|---|
| [ODBC] Linux에서 MS-SQL 접속하기 (0) | 2008.10.30 |
| [ER-Win] ERWin에서 MS-SQL 연결하기 (10) | 2008.10.08 |
| MySql Error - Client does not support authentication protocol requested by Server (0) | 2007.06.26 |
| MySQL Connection Error (0) | 2007.05.28 |
2009. 11. 6. 10:24
이전에 samba를 이용한 mount를 살펴봤는데 오늘 mount를 자동으로 하는 shell을 만들라고 했더니 mount를 할 때 사용되는 사용자 아이디와 패스워드가 있어야 하는것이다.
그래야 자동으로 해당 사용자를 이용해 mount를 할 수 있으니 말이다!
그래가지고 구글에 알아본 결과 -o 옵션이 존재한다. -o 옵션만 가지고 사용하는 것이 아니라 -o 옵션과 username, password 이 옵션들을 사용한다. 사용방법은 아래와 같다.
위와 같이 username과 password를 사용하면 된다.!!
그래야 자동으로 해당 사용자를 이용해 mount를 할 수 있으니 말이다!
그래가지고 구글에 알아본 결과 -o 옵션이 존재한다. -o 옵션만 가지고 사용하는 것이 아니라 -o 옵션과 username, password 이 옵션들을 사용한다. 사용방법은 아래와 같다.
# mount -t cifs -o username=guest //ip/mount_point mount_path
# mount -t cifs -o username=guest,password=pwd //ip/mount_point mount_path
# mount -t cifs -o username=guest,password=pwd //ip/mount_point mount_path
위와 같이 username과 password를 사용하면 된다.!!
'ººº::Development™:: > ::Linux™::' 카테고리의 다른 글
| [Cluster] rsh 설치 및 설정하기 (0) | 2010.04.08 |
|---|---|
| [Cluster] #1 Cluster 만들기 - 설치 (0) | 2010.04.01 |
| [Tip] 하나의 LanCard에 여러 아이피 Setting (0) | 2010.03.01 |
| [Linux] Samba mount (0) | 2009.09.01 |
| [Linux] SSH root접근 제한 (2) | 2009.05.18 |
2009. 11. 6. 09:30
시간이란..!
엄마 뱃속에서 짜잔 하고 엄마 아빠랑 마주했던게 엊그제 같은데 벌써 1년이란 시간이 흘러버렸다.
엄마 뱃속에서 짜잔 하고 엄마 아빠랑 마주했던게 엊그제 같은데 벌써 1년이란 시간이 흘러버렸다.

첫달부터 얼마전에 촬영한 돌사진까지.. 넘 다양한 표정과 다양함을 보여준 내 아들!ㅋㅋㅋ
:: 저에가 가장 소중한 사람입니다. 악플 사절!!~~^^ ::
'ººº::Photo™:: > ::상현지환™::' 카테고리의 다른 글
| [돌잔치] 12월 6일 스페셜가족의 특별한 돌잔치 (2) | 2010.01.05 |
|---|---|
| [돌잔치] 얼짱 이벤트 응모용!! (0) | 2009.10.25 |
| [포포상현] =ㅅ= 100일사진프로젝트!! (0) | 2009.03.31 |
| [포포상현] =ㅅ= 100일사진프로젝트!! (2) | 2009.03.31 |